Problem
구성원들의 데이터 활용 능력이 부족하다:
이 때 부족이란?
- 데이터를 잘 모르거나
- 쿼리문을 잘 사용하지 못하는 것
Solution : 물어보새(enhancing data literacy)
데이터 이해 : 데이터의 구조와 의미 파악 능력
->Data Discovery : 데이터의 다양한 정보 제공
데이터 생성 : 필요한 데이터 수집 및 가공 능력
->Text-to-SQL : 데이터 생성 기능 지원
데이터 분석 : 분석 기반의 인사이트 도출 능력
->Agentic Analytic : 데이터 분석 서비스 기능 제공
데이터 기반 의사소통 : 분석 결과를 효과적으로 전달하는 능력
->Knowledge Sharing: 지식 검색 및 공유 효율화 지원
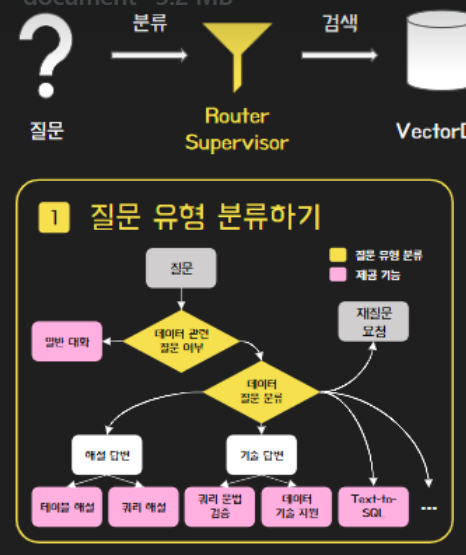
1. Data Discovery : 데이터 이해를 돕는 기능
- 해설 - 테이블, 쿼리문
- 검증 - 쿼리 문법
- 검색 - 테이블, 칼럼, 로그 데이터
- 지원 - 데이터 기술 문의
2. Text-to-SQL : 데이터 생성을 돕는 기능
- 생성 - 쿼리문
- (개인적인 생각) : MOTIVE project에서 동적 쿼리를 짜는 것은 필요 했기에 열심히 짰지만, 자동으로 조건 별로 나오는 쿼리가 있다? 우리가 springBoot를 통해 추상화된 시스템을 다루는 것처럼. 얼마나 좋은 시스템인가.라는 생각을 했다.

물어보새 아키텍처
1. Data Pipeline : VectorStore
2. Multi-Chains : R.A.G, Dynamic Prompt, Router Supervisor 등
3. LLMOps : 환경 구축
4. SlackBolt: Feedback Loop를 통한 개선사항 반영
● Data PipeLine, Multi-Chains 에 대한 이해가 있어야 코어 기능을 구현 할 수 있음
- Data Pipeline :
- 전처리 : LangChain
- Embedding Model: GPT? Llama?
- Vector Store
- Multi Chains
답변을 더 잘하게 하는 방법
1. Router Supervisor를 통한 질문 유형 분류
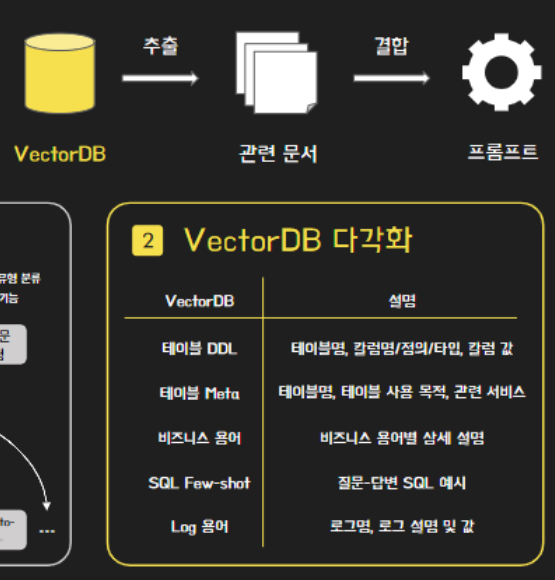
2. VectorDB 다각화
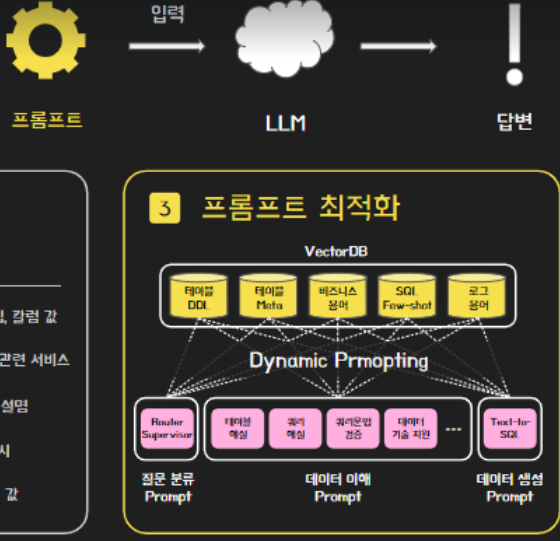
3. 프롬프트 최적화(LLM으로 가기전 검색한 문서와 프롬프트를 결합 시 최적화 하는 것이 Dynamic Prompting)
Knowledge Sharing

1. 검색
- 일반적인 검색 방식: Keyword
- 물어보새: Question
2. 요약
- 물어보새: 위키 주소 url만 가지고 원하는 형태로 문서를 요약함 (ex. 기획자 관점으로 요약해줘.)
3. 서포트 채널
- 물어보새: 알아서 답변해줌
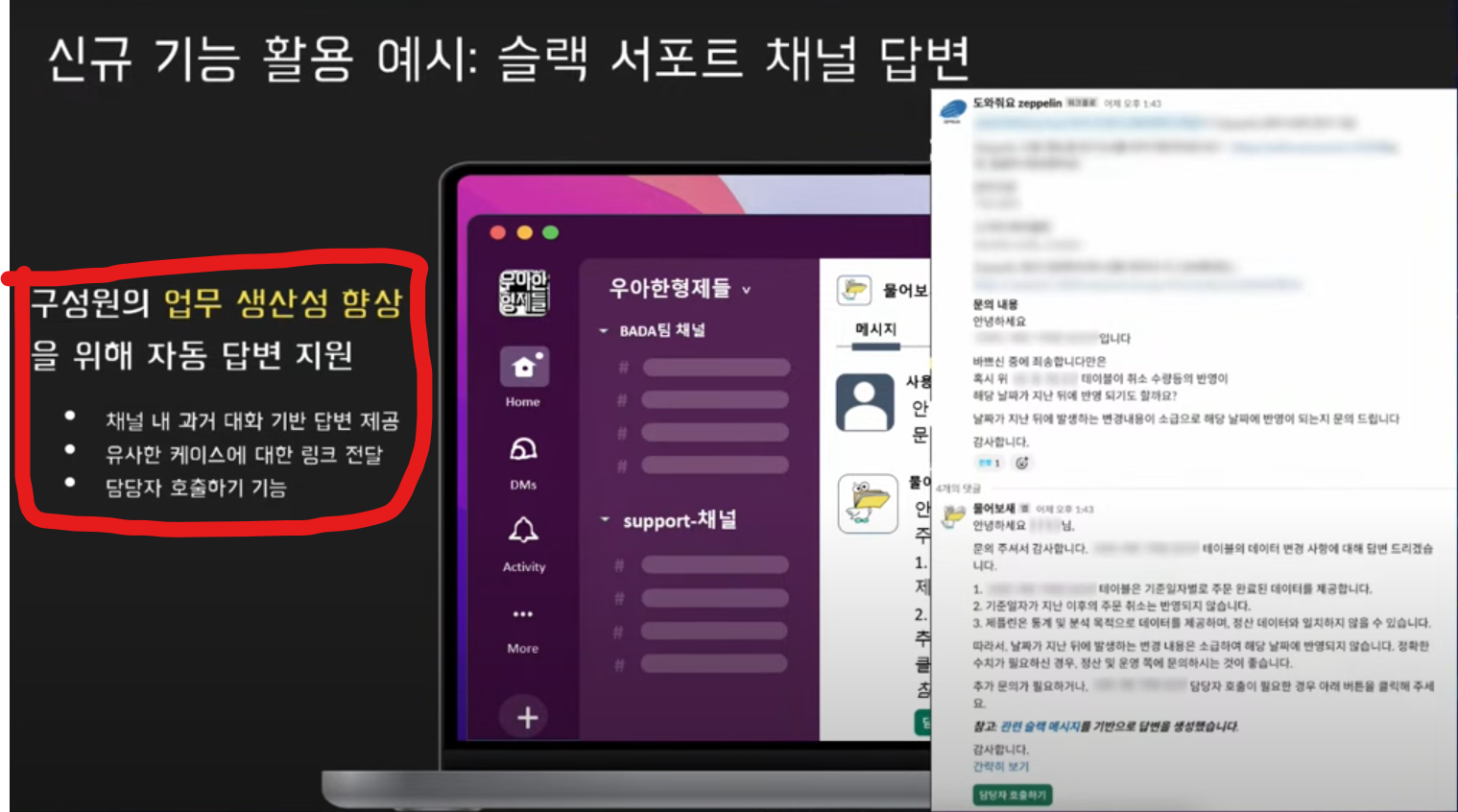
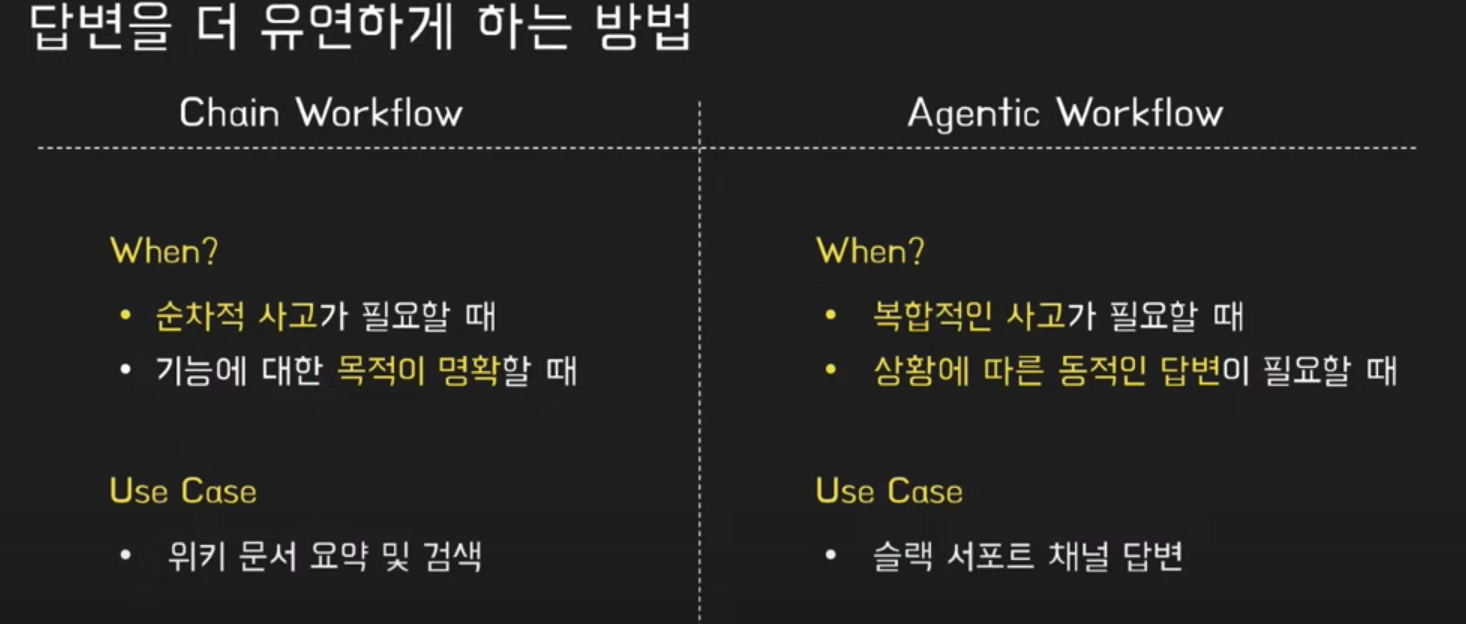
서포트 채널에서 답변을 더 유연하게 하는 방법
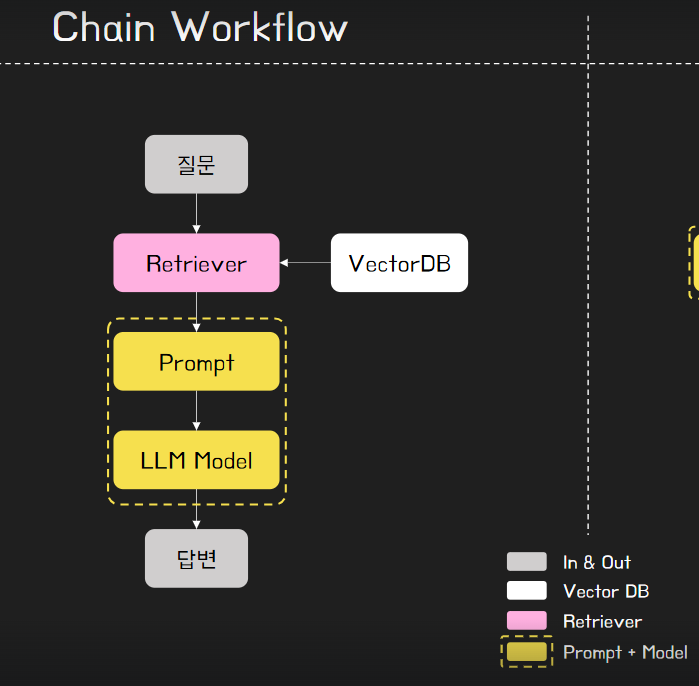
서포트 채널은 하나의 기능이지만, 질문의 유형이 다양하고, 각각의 질문에 정확도가 높아야 함.
-> 아마 위의 구조로는 정확도가 유의미하지 않았을 것으로 생각됨.
Solution
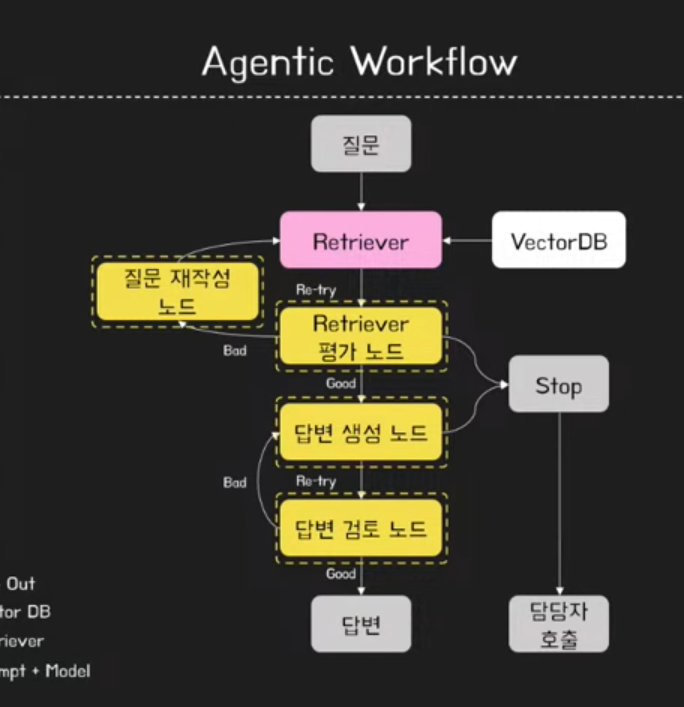
그래프 형태의 특징은 각각의 노드로 이루어져 있다는 것.
또한 각각의 노드가 prompt+LLM을 가지고 있는 것(Chain 역할을 하고 있다.)
(LangGraph 기반 구조)
Retriever를 검증하는 Retriver 평가 노드를 두었다.
각 단계에서 발생할 수 있는 오류를 최소화하였다.