사전 개념
B-Tree(Balanced Tree, 균형 트리)
- MariaDB가 B-Tree를 사용 시, tree에 노드에 해당하는 것은 페이지(Page)이다.
- 페이지란 16Kbyte 크기의 최소한의 저장 단위이다. → 아무리 작은 데이터를 한 개만 저장하더라도 한 개의 페이지(16Kbyte)를 차지하게 된다는 의미이다.
- 개념적으로 부를 때는 노드라 부르지만, MariaDB에서는 노드가 페이지가 되며 인덱스를 구현할 때 기본적으로 B-tree 구조를 사용한다.
- B-Tree 구조에서 데이터를 검색하는 방법(이때, 모든 데이터는 정렬되어 있다.)
- 우선 루트 페이지를 검색한다. → 정렬되어 있어서, 해당하는 데이터면 검색 끝, 아니면 범위에 따라서 깊이를 늘려가며 동일한 방식으로 데이터를 검색한다.

인덱스
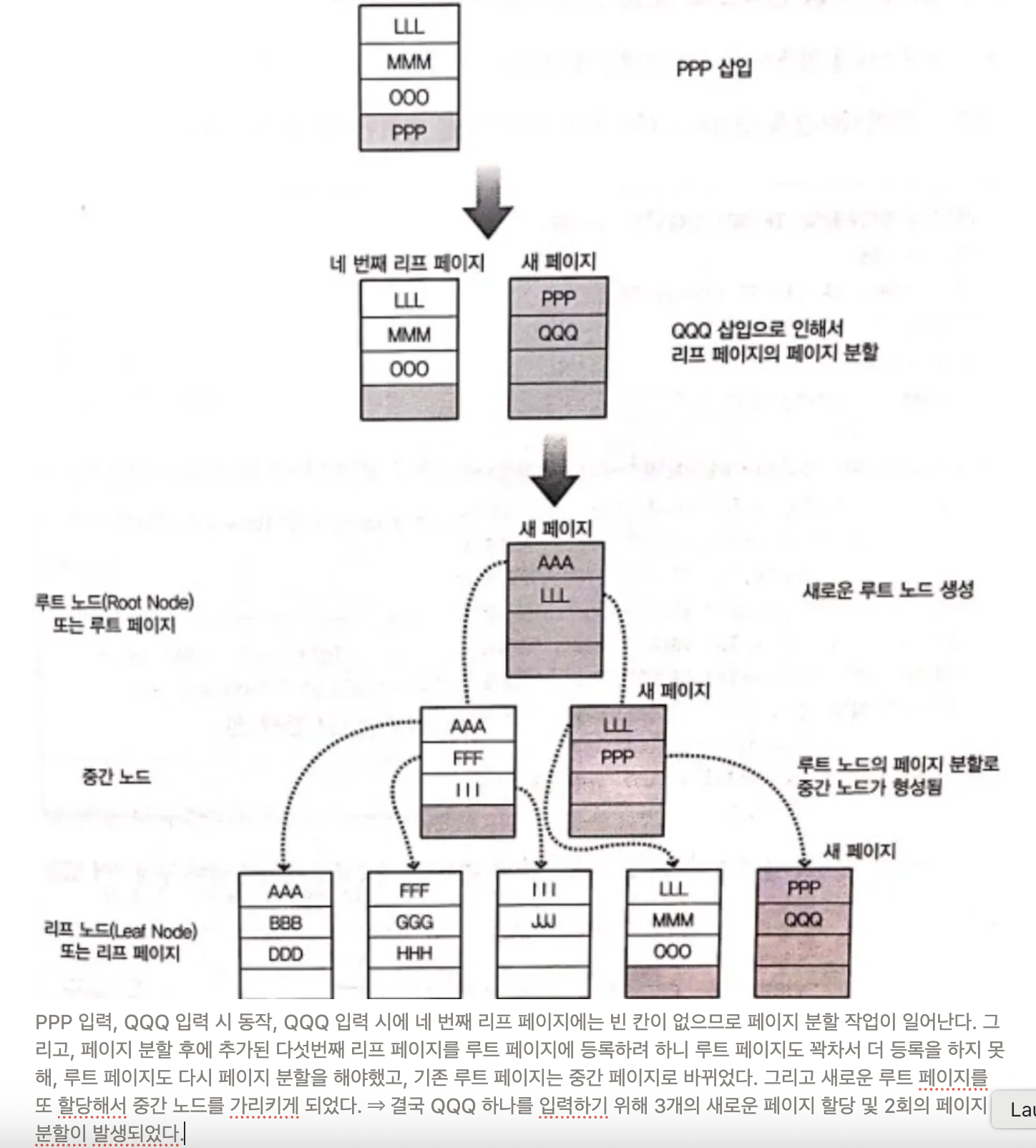
페이지 분할
- 인덱스를 구성하게 되면 데이터의 변경 작업(CUD) 시에 성능이 나빠지는 단점이 있다.
- 특히, INSERT 작업이 일어날 때 성능이 급격히 느려질 수 있다.
- 그 이유는 ‘페이지 분할’이라는 작업이 발생되기 때문이다.
- 특히, INSERT 작업이 일어날 때 성능이 급격히 느려질 수 있다.


클러스터형 인덱스와 보조 인덱스의 구조
- 클러스터형 인덱스 구성
- 루트 페이지와 리프 페이지 (중간 페이지가 있다면 중간 페이지도 포함)로 인덱스가 구성되어 있으며 동시에 인덱스 페이지의 리프 페이지는 데이터(리프페이지==데이터 페이지)를 가리킨다.
- 보조 인덱스 구성

- 검색 시 차이
- 클러스터형 인덱스
- 리프 페이지는 정렬되어 있고, 이 리프 페이지가 곧 데이터 페이지이므로, 범위로 검색 시에 아주 우수한 성능을 보인다.
- 보조형 인덱스
- 생각해보면 알겠지만. 포인터로 왔다갔다 하는 것 보면 읽는 페이지가 많다는 것을 알 수 있다.
- 클러스터형 인덱스
- 데이터 입력 시 차이
- 클러스터형 인덱스
- 페이지 분할, 순서 변경 등 성능에 주는 부하가 보조 인덱스보다 크다.
- 보조 인덱스
- 보조 인덱스는 데이터 페이지를 정렬하는 것이 아니므로 데이터 페이지(Heap 영역)의 뒤쪽 빈 부분에 삽입된다.
- 클러스터형 인덱스
결론
- 클러스터형 인덱스
- 클러스터형 인덱스생성 시에는 데이터 페이지 전체가 다시 정렬된다. 그러므로 이미 대용량의 데이터가 입력된 상태라면 업무시간에 클러스터형 인덱스를 생성하는 것은 심각한 시스템 부하를 줄 수 있으므로 신중하게 생각해야 한다.
- 클러스터형 인덱스는 인덱스 자체의 리프 페이지가 곧 데이터다. 그러므로, 인덱스 자체에 데이터가 포함되어 있다고 볼 수 있다.
- 클러스터형 인덱스보다 검색 속도는 더 빠르다. 하지만, 데이터의 입력/수정/삭제는 더 느리다.
- 클러스터 인덱스는 성능이 좋지만 테이블에 한 개만 생성할 수 있다. 그러므로, 어느 열에 클러스터형 인덱스를 생성하는지에 따라서 시스템의 성능이 달라질 수 있다.
- 보조 인덱스
- 보조 인덱스의 생성 시에는 데이터 페이지는 그냥 둔 상태에서 별도의 페이지에 인덱스를 구성한다.
- 인덱스 자체의 리프 페이지는 데이터가 아니라 데이터가 위치하는 주소 값(RID)이다. 클러스터형보다 검색 속도는 더 느리지만 데이터의 입력/수정/삭제는 덜 느리다.
- 보조 인덱스는 여러 개 생성할 수 있다. 하지만, 함부로 남용할 경우에는 오히려 시스템 성능을 떨어뜨리는 결과를 초래할 수 있으므로 꼭 필요한 열에만 생성하는 것이 좋다.
클러스터형 인덱스와 보조 인덱스가 혼합되어 있을 경우
- 혼합된 인덱스의 내부 구성

- 클러스터형 인덱스의 경우에는 그대로 변함이 없다. 보조 인덱스는 예상과 다른데,,
- 보조 인덱스의 루트 페이지와 리프 페이지의 키 값이 지정한 컬럼으로 구성되어 있으므로 지정한 컬럼으로 정렬되었다.
- 클러스터형 인덱스 페이지가 없었다면 아마도 ‘데이터 페이지의 주소 값’으로 구성되어 있었겠지만, 지금은 클러스터형 인덱스의 키 값을 가지게 된다.
- 보조 인덱스를 검색한 후에는 모든 경우가 다시 클러스터형 인덱스의 루트 페이지부터 검색을 한다.
→ 이런 구성을 한 이유
기존처럼 오프셋으로 구성하면 더 빠르겠지만 서로 관련없이 구성했을 때의 경우에 한한다.
- 만약 위의 그림처럼(클러스터형 인덱스의 키 값을 value값으로 가질 때) 있을 때, 행이 추가된다고 생각해볼 때, 클러스터형 인덱스는 페이지 분할 등의 작업이 발생 되고, 보조 인덱스에도 데이터의 리프페이지에 추가되면서 데이터의 순서가 약간 변경될 뿐이다.
- 하지만 보조 인덱스의 리프 페이지가 ‘데이터 페이지의 주소 값’으로 되어 있을 때, 데이터의 삽입으로 인해 클러스터형 인덱스의 리프 페이지가 재구성 되어 데이터 페이지의 번호 및 ‘#오프셋’이 크게 변경된다. 그런 경우, 보조 인덱스 역시 많은 부분이 다시 구성되어야 한다.
- 결국은 성능 부하를 줄이기 위해, 이런 구조가 된 것임.
인덱스 사용 팁
- 인덱스를 검색하기 위한 일차 조건은 WHERE절에 해당 인덱스를 생성한 열의 이름이 나와야 한다. 물론 WHERE절에 해당 인덱스를 생성한 열 이름이 나와도 인덱스를 사용하지 않는 경우도 많다.
- DBMS에서 적정 수량의 데이터를 읽을 경우에는 인덱스를 사용한다.
- 기존에 생성해 놓은 보조 인덱스 중에서 전체 데이터의 대략 10~20% 이상을 스캔하는 경우에는 인덱스를 사용하지 않고 테이블 검색을 실시한다. → DBMS 자체에서 효율적이라 판단되는 걸 함
- 인덱스가 생성된 열에 함수나 연산을 가하게 되면, 인덱스를 사용하지 못한다.
- 데이터 중복도가 높은 열에 인덱스를 사용하는 것이 조금의 효율은 있으나, 인덱스 관리 비용과 INSERT 등의 구문에서는 오히려 성능이 저하될 수 있다.
- 사용하지 않는 인덱스는 제거하자.